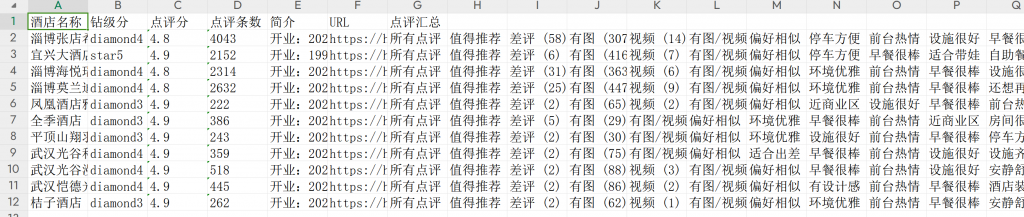
[爬虫]爬取携程指定酒店的评价汇总
要求:
1、爬取多家指定酒店的评价汇总
代码:
#单 位:常州旺龙
#作 者:OLDNI
#开发日期:2023/10/24
import json
import os
import re
import time
from datetime import datetime, timedelta
from bs4 import BeautifulSoup
from openpyxl import Workbook
from selenium import webdriver
from selenium.webdriver.common.by import By
today_obj=datetime.now()
today_date=today_obj.strftime('%Y-%m-%d')
date_interval=timedelta(days=1)
tomorrow_obj=today_obj+date_interval
tomorrow_date=tomorrow_obj.strftime('%Y-%m-%d')
#此处添加酒店
hotels_dict={
'淄博张店希尔顿欢朋酒店':f'https://hotels.ctrip.com/hotels/detail/?hotelId=1379642&checkIn={today_date}&checkOut={tomorrow_date}&cityId=542',
'宜兴大酒店':f'https://hotels.ctrip.com/hotels/detail/?hotelId=666485&checkIn={today_date}&checkOut={tomorrow_date}&cityId=537',
'淄博海悦瑞景酒店':f'https://hotels.ctrip.com/hotels/detail/?hotelId=95265902&checkIn={today_date}&checkOut={tomorrow_date}&cityId=542',
'淄博莫兰迪酒店(八大局店)':f'https://hotels.ctrip.com/hotels/detail/?hotelId=100542386&checkIn={today_date}&checkOut={tomorrow_date}&cityId=542',
'凤凰酒店雅居(平顶山市开源路步行街店)':f'https://hotels.ctrip.com/hotels/detail/?hotelId=108599586&checkIn={today_date}&checkOut={tomorrow_date}&cityId=3222',
'全季酒店(平顶山万达广场店)':f'https://hotels.ctrip.com/hotels/detail/?hotelId=105635773&checkIn={today_date}&checkOut={tomorrow_date}&cityId=3222',
'平顶山翔羽智慧酒店(文化宫店)':f'https://hotels.ctrip.com/hotels/detail/?hotelId=96521686&checkIn={today_date}&checkOut={tomorrow_date}&cityId=3222',
'武汉光谷科技会展中心希尔顿欢朋酒店':f'https://hotels.ctrip.com/hotels/detail/?hotelId=110707379&checkIn={today_date}&checkOut={tomorrow_date}&cityId=477',
'武汉光谷漫心酒店':f'https://hotels.ctrip.com/hotels/detail/?hotelId=76505443&checkIn={today_date}&checkOut={tomorrow_date}&cityId=477',
'武汉恺德光谷城际酒店':f'https://hotels.ctrip.com/hotels/detail/?hotelId=100465216&checkIn={today_date}&checkOut={tomorrow_date}&cityId=477',
'桔子酒店(武汉光谷大学园路店)':f'https://hotels.ctrip.com/hotels/detail/?hotelId=105595985&checkIn={today_date}&checkOut={tomorrow_date}&cityId=477',
# '':'',
}
print(f'正在爬取{len(hotels_dict)}家酒店')
#创建浏览器
options=webdriver.ChromeOptions()
options.add_experimental_option('detach',True)
options.add_argument('--disable-blink-features=AutomationControlled')
browser=webdriver.Chrome(options=options)
browser.implicitly_wait(10)
# 登录携程页面,使用cookies登录,方便打开详情页
browser.get('https://hotels.ctrip.com/hotels/list?countryId=1&city=537&checkin=2023/10/19&checkout=2023/10/20&optionId=537')
# 添加cookies信息
with open('15312585581_xc_cookies.json', encoding='utf-8') as f:
cookies = json.loads(f.read())
for x in cookies:
browser.add_cookie(x)
browser.get('https://hotels.ctrip.com/hotels/list?countryId=1&city=537&checkin=2023/10/19&checkout=2023/10/20&optionId=537')
#创建excel表
wb=Workbook()
sheet=wb.active
header=['酒店名称','钻级分','点评分','点评条数','简介','URL','点评汇总']
sheet.append(header)
#酒店名是从A2开始对应第一家,A3对应第二家,依次类推.用于关联存放酒店详情页数据的sheet表
n=2
for hotel_name,hotel_url in hotels_dict.items():
print(hotel_name,hotel_url)
#打开新的标签页
new_table = f'window.open("{hotel_url}")'
browser.execute_script(new_table)
time.sleep(3)
browser.switch_to.window(browser.window_handles[-1])
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
level = soup.select_one('div.detail-headline_title > img')['src'].split('_')[3]
score=soup.select_one('span.detail-headreview_score_box > b').text
#评分超过1000的写法是1,000 多了逗号。
#这里的思路是把所有的数字找出来,再组合成一个字符
score_number_init=soup.select_one('p.detail-headreview_all').text
score_number_list= re.findall('\d+', score_number_init)
score_number=''
for s in score_number_list:
score_number+=s
profile=soup.select_one('.basic-sub.clearfix').text
data=[hotel_name,level,score,score_number,profile,hotel_url]
# sheet.append(data)
# 创建每家以酒店名称命名的数据表并关联
# wb.create_sheet(hotel_name)
# location = 'A' + str(n)
# n += 1
# cell = sheet[location]
# cell.value = f'=HYPERLINK("#\'{cell.value}\'!A1","{cell.value}")'
# sheet=wb[hotel_name]
# header=['点评汇总']
# sheet.append(header)
#点击点评
# browser.find_element(By.CSS_SELECTOR,'div.detail-hotelnavi_list > span:nth-child(2)').click()
comment_tags_list=soup.select('.u-btn.u-btn-filter.u-btn-sm.u-btn-radiuslg')
print(f'共有{len(comment_tags_list)}个标签')
data_comment=[]
for comment_tag in comment_tags_list:
data_comment.append(comment_tag.text)
data_all=data+data_comment
sheet.append(data_all)
sheet=wb['Sheet']
#关闭新开的标签页
browser.close()
browser.switch_to.window(browser.window_handles[0])
time.sleep(2)
#关闭浏览器(最后一个标签页)
# browser.close()
wb.save('获取指定酒店的点评.xlsx')
os.startfile('获取指定酒店的点评.xlsx')效果: